计算机视觉可以分为两大方向:基于学习的方法和基于几何的方法。其中基于学习的方法最火的就是深度学习,而基于几何方法最火的就是视觉SLAM(Simultaneous Localization and Mapping)
图像分割
图像分割:图像分割就是把图像分成若干个特定的、具有独特性质的区域并提出感兴趣目标的技术和过程。 它是由图像处理到图像分析的关键步骤。图形分割是Target Segmentation,是data/image segmentation的一种。任务是把目标对应的部分分割出来。对于一般的光学图像而言,分割像素是一个比较常见的目标,就是要提取哪一些像素是用于表述已知目标的。这种Segmentation可以是一个分类(classificatio)问题,就是把每一个pixel做labeling,提出感兴趣的那一类label的像素。也可以是clustering的问题,即是不知道label,但需要满足一些optimality,比如要cluster之间的correlation最小之类的。(像素级的对前景与背景进行分类,将背景剔除)

目标检测
目标检测:目标检测是Target Detection。最早的detection system应该是搞雷达的人首先提出并且heavily study的,最简单的任务就是从看似随机(random)又充满干扰(interference)和噪音(noise)的信号中,抓取到有信息的特征(information-bearing pattern)。最简单的一个栗子,就是当你拿到一段随机的雷达回波,可以设置一个threshold,当高于这个threshold,就认为是探测到了高速大面积飞行器之类的高回波的目标。当然,这里面的threshold该怎么设计,涉及到False Alarm和Miss Detection之间的平衡。人们往往需要寻找最佳的transform或者domain去对信号进行分析。(定位目标,确定目标位置及大小)
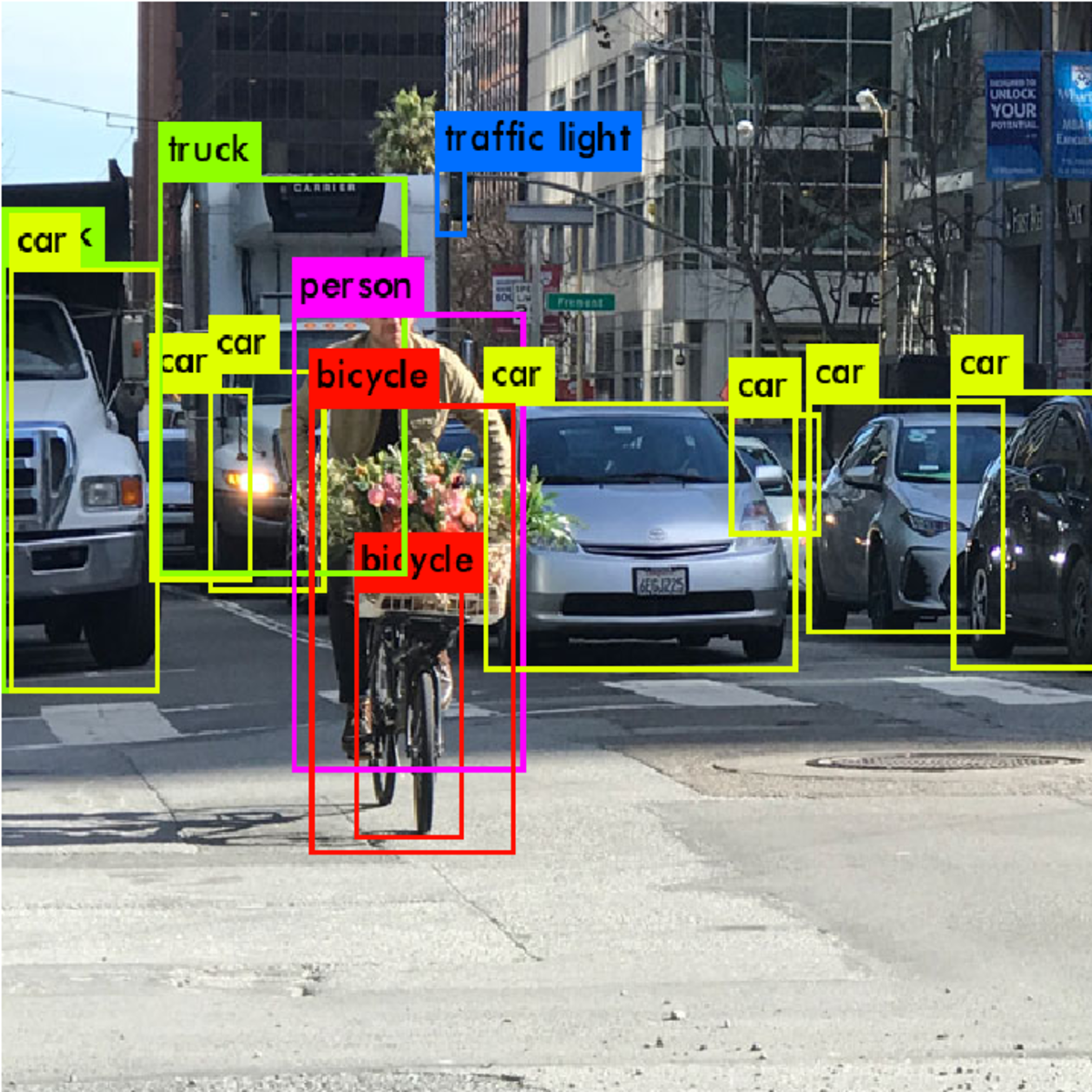
从输入和输出来比较的话,物体检测的输入和图像分割的输入都是一样的.
一般情况下都是x * y * 3的数组(可以理解为RGB各一层)或者是x * y的
binary image. 物体检测的输出一般都是一个bounding
box的列表,而图像分割的输出是一个矩阵, 用来表示mask.
分割和检测融合?
目前也有很多算法将分割和检测进行融合:比如:
- RDSNet: A New Deep Architecture for Reciprocal Object Detection and Instance Segmentation
- Joint 3D Instance Segmentation and Object Detection for Autonomous Driving
- Gated-SCNN: Gated Shape CNNs for Semantic Segmentation
- etc.
通过一个/一种深度学习的结构是很难把这两种不同的任务结合到一起的,以Gated-SCNN: Gated Shape CNNs for Semantic Segmentation为例, 作者认为通过一个深度CNN网络同时处理图像的颜色,形状和纹理信息用于像素级分类可能不是理想的做法,因此该论文提出two-stream CNN结构,将形状信息作为单独处理的分支。两分支包括shape stream和regular stream,二者相互协作且是并行的,通过设计的门控卷积层和局部监督损失有效地移除了噪声并帮助shape stream仅仅处理与边界相关的信息,然后通过ASPP模块保留多尺度上下文信息,融合regular stream的语义区域特征和shape stream的边界特征产生refined的分割输出,尤其refine在边界周围的像素分割。