Sorted String Table(SSTable)--是存储,处理和交换数据集的最流行的输出之一。正如名字本身所包含的意思一样,SSTable是一个简单的抽象,用来高效地存储大量的键-值对数据,同时做了优化来实现顺序读/写操作的高吞吐量。
什么是 SSTable?
Google 发布的Bigtable论文中解释道:SSTable提供一个可持久化[persistent],有序的、不可变的从键到值的映射关系,其中键和值都是任意字节长度的字符串。SSTable提供了以下操作:按照某个键来查询关联值,可以指定键的范围,来遍历其中所有的键值对。每个SSTable内部由一系列块(block)组成(通常每块大小为64KB,是可配置的)。使用存储在SSTable结尾的块索引(block index)来定位块;当SSTable打开时,索引会被加载到内存里。一次磁盘寻道(disk seek)就可以完成查询(lookup)操作:首先通过二分查找在存储在内存的索引中找到对应的块,然后从磁盘上读取这块内容。SSTable也可以完整地映射到内存里,这样在执行查询和扫描(scan)的时候就不用操作磁盘了.
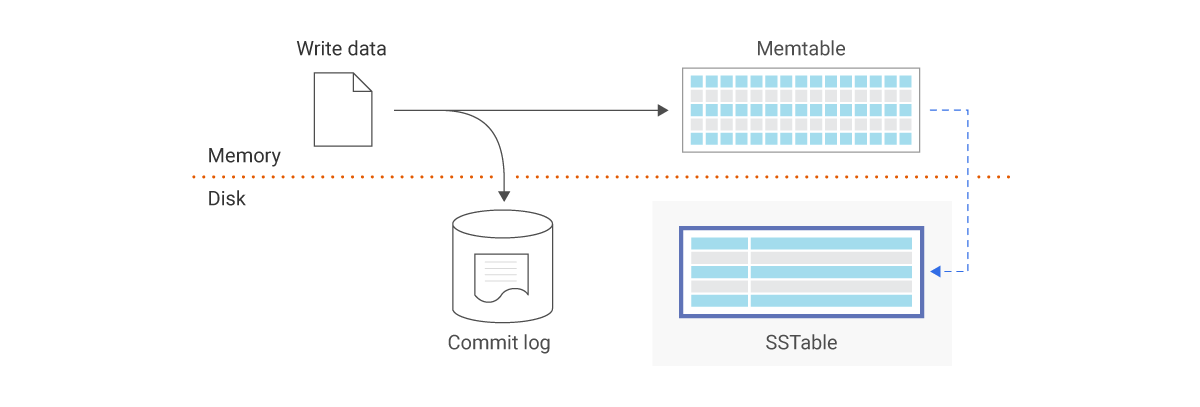
Scylladb在其官网(What is a SSTable? Definition & FAQs | ScyllaDB)中做出了以下解释:
Sorted Strings Table (SSTable) is a persistent file format used by ScyllaDB, Apache Cassandra, and other NoSQL databases to take the in-memory data stored in memtables, order it for fast access, and store it on disk in a persistent, ordered, immutable set of files. Immutable means SSTables are never modified. They are later merged into new SSTables or deleted as data is updated.
其实除了Scylladb以外,当有很多公司使用SSTable,这些SSTable有些许轻微的不同。这里我们只研究BigTable中的SSTable。
MemTable是一种在内存中保存数据的数据结构,然后再在合适的时机,MemTable中的数据会flush到SSTfile中。MemTable既可以支持读服务也可以支持写服务,写操作会首先将数据写入Memtable,读操作在querySSTfiles之前会首先从MemTable中query数据(因为MemTable中的数据一直是最新的)。一旦MemTable满了,就会转换为只读的不可改变的,然后会创建一个新的MemTable来提供新的写操作。后台线程负责将MemTable中的数据flush到SSTfile,然后这个MemTable就会被销毁。
SSTable 有何作用?
01:储存格式
在新数据写入时,这个操作首先提交到日志中作为redo纪录,最近的数据存储在内存的排序缓存memtable中;旧的数据存储在一系列的SSTable 中。在recover中,tablet server从METADATA表中读取metadata,metadata包含了组成Tablet的所有SSTable(纪录了这些SSTable的元 数据信息,如SSTable的位置、StartKey、EndKey等)以及一系列日志中的redo点。Tablet Server读取SSTable的索引到内存,并replay这些redo点之后的更新来重构memtable。在读时,完成格式、授权等检查后,读会同时读取SSTable、memtable(HBase中还包含了BlockCache中的数据)并合并他们的结果,由于SSTable和memtable都是字典序排列,因而合并操作可以很高效完成。
02:压缩(Compaction)过程中的使用
随着memtable大小增加到一个阀值,这个memtable会被冻住而创建一个新的memtable以供使用,而旧的memtable会转换成一个SSTable而写道GFS中,这个过程叫做minor compaction。这个minor compaction可以减少内存使用量,并可以减少日志大小,因为持久化后的数据可以从日志中删除。在minor compaction过程中,可以继续处理读写请求。 每次minor compaction会生成新的SSTable文件,如果SSTable文件数量增加,则会影响读的性能,因而每次读都需要读取所有SSTable文件,然后合并结果,因而对SSTable文件个数需要有上限,并且时不时的需要在后台做merging compaction,这个merging compaction读取一些SSTable文件和memtable的内容,并将他们合并写入一个新的SSTable中。当这个过程完成后,这些源SSTable和memtable就可以被删除了。 如果一个merging compaction是合并所有SSTable到一个SSTable,则这个过程称做major compaction。一次major compaction会将mark成删除的信息、数据删除,而其他两次compaction则会保留这些信息、数据(mark的形式)。Bigtable会时不时的扫描所有的Tablet,并对它们做major compaction。这个major compaction可以将需要删除的数据真正的删除从而节省空间,并保持系统一致性。
SSTable 设计成immutable的优点
- 在读SSTable是不需要同步。读写同步只需要在memtable中处理,为了减少memtable的读写竞争,Bigtable将memtable的row设计成copy-on-write,从而读写可以同时进行。
- 永久的移除数据转变为SSTable的Garbage Collect。每个Tablet中的SSTable在METADATA表中有注册,master使用mark-and-sweep算法将SSTable在GC过程中移除。
- 可以让Tablet Split过程变的高效,我们不需要为每个子Tablet创建新的SSTable,而是可以共享父Tablet的SSTable。
更多
《Bigtable: A Distributed Storage System for Structured Data》 《Bigtable: A Distributed Storage System for Structured Data》论文翻译